| |
Description |
| | TextSleuthTextSleuth is a brute-force search utility to identify non-standard text encoding formats.
It supports multi-threading for enhanced performance, as well as a host of flexible options. It performs its scan by sliding a window over binary data and checking for repeating byte patterns based on user-defined encoding rules. It calculates byte strides between elements (accounting for wildcards), maps pattern IDs to actual byte sequences, and validates structural consistency. The algorithm is optimized by:
- Precomputing offsets and pattern span.
- Skipping chunks early if unique group counts don’t match.
- Using multithreading with a shared queue for parallel file processing.
- Minimizing disk I/O by reading entire files into memory once.
TextSleuth's primary target users are hackers and reverse-engineers developing video game translation patches, especially those considered "retro" where custom text encoding formats were often used (rather than standards like ASCII or Shift-JIS).
Current VersionTextSleuth is currently at version 1.1....
Changelog - Version 1.1 (2025-04-23)
- Added Shift-JIS encoding support for pattern file.
- Fixed incorrect description of auto-calculated worker thread count.
- Version 1.0 (2025-04-19)
BenchmarksWith support for multi-threading, TextSleuth can be scaled as desired. By default, it will consume one fewer thread than the total logical processor count of the host computer on which it's executed.
On an AMD Ryzen 5 4600H running at 3.0 GHz with six cores and 12 logical processors (threads), where TextSleuth is consuming 11 threads, approximately 20 MB of data can be searched per minute.
UsageTextSleuth is a command-line utility to be invoked as follows.
Long option format:
| | | text_sleuth --parameter <value> |
Short option format:
Below are a list of all available options, both required and optional.
Code: | | | Required: -l, --length NUM - Encoded character byte length (e.g., 1, 2) -p, --pattern FILE - Path of pattern file -s, --source DIR or FILE - Path of folder to recursively scan (or single file) Optional: -w, --wildcard NUM - Number of wildcard bytes in between encoded characters (e.g., 1, 2) -i, --ignore STR - Comma-separated list of file extensions to ignore (e.g., sfd,adx,pvr) -c, --thread-count NUM - Number of threads to use (default is CPU core count minus one) |
Example ScenarioConsider the following example for the FM Towns game "Phobos".
After some analysis of the game data, it was discovered that in-game dialogue text was not compressed, but definitely stored using a non-standard text encoding format.
To uncover the custom character encoding format leveraged by the game, the user finds a chunk of text containing a sufficient number of repeating characters. Since TextSleuth will perform a brute-force search, the user wants to eliminate as many false-positives as possible by identifying sequences of characters that are likely to be unique.
Below is one such example, where contains 16 characters, five of which are not unique (i.e., they are repeated).

After identifying such a text chunk, the user has two choices for building their pattern file.
If the target game's text is Japanese, one can create a text file with Shift-JIS encoding containing the direct transcription, being sure to separate each character with an empty space. Note that UTF-8 or other encoding formats are not supported.
Alternatively, users can transcribe a pattern using any ASCII characters of their choice. For example, one can assign a given Japanese character to the letter , or to the number .
Below is an example of translating the string of text into a valid pattern.

Once the pattern has been identified, it's then to be written to a text file.
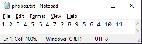
With this pattern saved as , and the extracted game data stored in a folder named , it's time to construct the first search command.
For the initial attempt, the user assumes a two-byte format with no wildcards in between.
| | | text_sleuth.exe --length 2 --pattern phobos.txt --source inp\ |
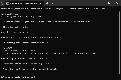
As seen above, a match was found on the first attempt, and in a total of five seconds! TextSleuth is reporting that an array of bytes matching the defined search criteria pattern was found at offset inside the file .
Consider the matched byte array. It appears to be potentially valid, as a discernible structure begins to take shape for a proposed custom text encoding format.
| | | 14ed 1c0a 1c9c 1c43 1c6c 1c1a 1c43 0cbb 1c0a 0cda 1ceb 1c6c 1c1a 1c43 0cc3 1487 |
As an initial test, the user will repeat the first two-byte sequence () a total of ten times to see if the change is reflected in the game itself.
As seen below, the first character in the text chunk, , is indeed repeated ten times!

It's at this point that the user undergoes the process of mapping out the table of all characters supported by the game, after which text extraction and additional hacking efforts can take place.
Note that should the initial scan failed to produce meaningful results, the user would attempt again with different options, such as a byte-length of one (instead of two). Additionally, wildcard options may be used.
For example, one could imagine a scenario where the matched data from this example used terminator bytes in between encoded characters, as shown below.
Code: | | | 14 ed 00 1c 0a 00 1c 9c 00 1c 43 00 1c 6c 00 1c 1a 00 1c 43 00 0c bb 00 1c 0a 00 0c da 00 1c eb 00 1c 6c 00 1c 1a 00 1c 43 00 0c c3 00 14 87 00 |
TextSleuth would fail to identify this byte array as a match unless the option was used. See example command below.
| | | text_sleuth.exe --length 2 --pattern phobos.txt --source inp\ --wildcard 1 |
Another example could include two wildcard bytes, where ends character one, ends characters two, and so on.
Code: | | | 14 ed 00 01 1c 0a 00 02 1c 9c 00 03 1c 43 00 04 1c 6c 00 05 1c 1a 00 06 1c 43 00 07 0c bb 00 08 1c 0a 00 09 0c da 00 0a 1c eb 00 0b 1c 6c 00 0c 1c 1a 00 0d 1c 43 00 0e 0c c3 00 0f 14 87 00 10 |
In such a case, the following command could be used to successfully match it.
| | | text_sleuth.exe --length 2 --pattern phobos.txt --source inp\ --wildcard 2 |
|
|





