| Home | Forums | What's new | Resources | |
| Translating/hacking 3x3 Eyes Seima Densetsu for Mega CD |
| Ginza - Aug 19, 2025 |
| Ginza | Aug 19, 2025 | ||
| Hi all! Long time lurker. I've been doing small time rom-hacking for a while, and for some reason I just love the Mega CD. It just seems to have had a lot of potential which was unused, and/or not available to non-japanese audiences. Lately I've been researching Illusion City a bit - though I don't want to spend too much time on that, as the MSX version is just about completed by a MSX group. So, I changed over to 3x3 Eyes Seima Densetsu. It's an interesting RPG made by Sega themselves, with lots of Sega references (I even noticed the Sonic "ring" sound at one point). You can also find a Game Gear White in-game and sell it, and there are many references to contemporary games (Streets of Rage 2, Puyo Puyo etc.) and much more... It is also one of the better (the best?) 3x3 Eyes games for any console, according to some Japanese sources. So - worth investigating for any Sega fan! My main problem is that I have a busy personal life, and progress will be very slow. It seems to be a huge game (it has 231 unique files (!) with scenario/event text, but also lots of text describing items, side quests, in-game hint system etc.). On the plus side, the scenario files seem to have lots of unused space between separate blocks of data, and should easily fit an English translation. Also they used the standard Sega LZ (Kosinski) compression for graphics and tilemaps, which is very well researched already. Status for now is * Completed table file * 8x16 font function assembly hacked/expanded from only numbers to complete ASCII alphabet. * Static menu text tilemap translation underway * Documentation of control codes underway * Lots of research of files, functions and compressed data done Major hurdle is that to display text the game uses a pointer table which points to one of many control codes. These control codes can do many things, including display text (not always) according to another pointer (embedded pointer I guess you could call it, though it is not neccessarily within the text data). This means you need to track pointers when you dump the script, and recalculated them when you insert (recompile?) it. I don't know any programming, but have gotten by ChatGPT programmed tools. Inserted text pointers have been hand calculated so far, but I won't finish in 100 years doing this for the whole game Also all translation is AI based for now - this is not the goal, but just to have some temp text to test with... I try to keep things as open as possible, as there is a large chance I cannot continue researching at some point, or it will go way too slow - so I hope someone else will pick up the work and contribute. I am a huge believer in open sourcing translations. Long term goal would be to have more Mega CD games translated. Here you can find my published notes so far on Github: https://github.com/Ginza25/3x3eyesMCD/... My hope is mostly to get others interested in contributing, so that it can become more of a collective effort - this is definitely not a project with a any deadline in mind. | |||
| Toppis | Aug 21, 2025 | ||
| Oh, this looks so good! I will definitely try it when it’s released | |||
| Ginza | Sep 22, 2025 | ||
| Progressing slowly. Started to understand the "event opcodes" the game uses to move around sprites/NPCs and sprites during events/cutscenes, which are separate from the "text opcodes" which relate to which text is displayed etc (conditions) and text control codes which deal with presentation/formatting of text. There are about 80 event opcodes, which would be very tedious to try to understand, however with the wonders of ChatGPT, I just fed it all 80 opcode functions in 68000 assembly, and it analyzed and provided name suggestions for all of them. Checking a few of the manually it seems the AI hit rate was pretty OK. Hard to overestimate how useful AI can be when looking at these old games... | |||
| Ginza | Sep 23, 2025 | ||
| Now thanks to ChatGPT, Ghidra and BlastEm, I have a small program which "decompiles" the text opcodes in Event files. Currently successfully decompiles the whole Hong Kong start scenario (EV00006.DAT). Opcodes are specified in a YAML file, e.g. like this: 0x56: name: SubtractImmediateFromLastResult arg_count: 1 arg_widths: [1] arg_is_offset: [false] continues: true I know its not obvious, but this seems amazing to me, with no actual programming skills, just "Vibe coding" - first steps towards a dumper, including embedded offsets! You can find the code on the Github repository: https://github.com/Ginza25/3x3eyesMCD... 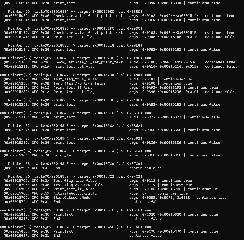 | |||
| derek (ateam) | Sep 23, 2025 | ||
| Whether you can write this code yourself or not, to have the resolve to try and use all the tools at your disposal and actually make progress deserves commending. Best of luck in your project! | |||
| Ginza | Sep 24, 2025 | |||
Thanks for the encouragement! Still hoping someone interested in Sega Mega CD will want to investigate/help out. Would be fun to have the first Mega CD exclusive (not counting the Phantasy Star compilation) games being translated! Though for now I'll try to post everything on github and update along the way. Without going into politics, I was actually encouraged by the Princess Crown translation, where someone else was able to pick up the work after it became dormant... I thought that was a great result, as long as everyone is credited, of course. I will be unhappy if all my work goes to waste, because I couldn't finish, but we'll see how far I get. I think making a dumper is realistic with what I know now, and then a translator could go through the script. The main challenge to my abilities (remember - vibe coding) is to make a re-insertion utility, as there is a lot of offsets which needs re-calculating, but I'm kind of optimistic. | ||||
| derek (ateam) | Sep 24, 2025 | |||
I have written dozens of such tools for games at this point, and I honestly can't envision using an LLM to write a text injector for complicated text-heavy games with scripting engines full of control codes and pointer tables. For the sake of your project, I'd be happy to be proven wrong though! That said, if you make really good progress, you may be able to attract the attention of some programmers/romhackers who'd be happy to step in and assist. | ||||
| Ginza | Sep 24, 2025 | |||
I will use the opportunity to pitch the project a bit for anyone reading with experience and/or motivation to join forces!
As a progresss update: I've asked ChatGPT to update the dumper to follow opcode jumps, and it seems to work. It still stops on unrecognized opcodes, but it's not that hard to find the arguments and add it to the YAML opcode file which the dumper reads, and then progress further. The game has 121 text opcodes and 80 event opcodes, but many overlap and most are not used often it seems. I have managed clean opcode "dumps" of some of the scenario files already. I just feel the difficult part is to re-insert and update all these layers upon layers of offsets... Though I also was skeptical I could get this far... UPDATE: In 15 minutes I got ChatGPT to add an "text offset" argument to the opcodes in the YAML file, and print if encountered according to the table file... It works... very nice! Basically this is a working dumper - I think. It's not designed for re-insertion, but curious if I'm missing something in the dump which is included/needed for translating. For context I guess it would be nice to have a description of each flag - not only hex values - and possibly actual graphics portraits of the relevant characters, but I think that might not be worth the effort, more quality of life than anything else... 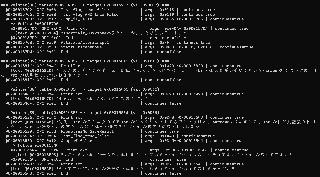 | ||||
| Ginza | Nov 3, 2025 | ||
| Small status report. I've updated the CSV file to include relevant text offsets for all EV-files, so this doesn't need to be specified manually. I also added definitions of about 50 text opcodes (out of about 80 total) to the YML file, which allows almost all (200 out of 210 or so) event file text segments to be dumped (excluding shops). Also added another data field "flags", which reads a description of each flag, given in another TBL file. In sum this makes it possible to dump almost all the text of the game - and also easily add descriptions to flags to give some context when reading the dump. It should basically be possible to translate the script from this, I think. Insertion would be the major next step. Still there a few outlier EV-files - some may have bugs and some opcodes may still need definitions. Also shop data is not dumpable yet - this is even more standardized, so should be doable, but needs work. You can see an example of the dumped data below. Updates are posted to the github repo. 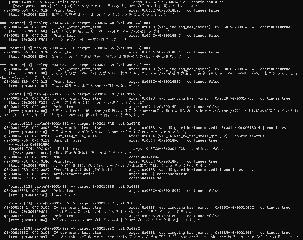 | |||
| LTH | Nov 5, 2025 | ||
| hopefully you can find a way to add subtitles to the voice acted cutscenes | |||
| Ginza | Nov 5, 2025 | ||
| Personally I wouldn't mind an AI translation of the audio using the original voices. Adding subtitles should also be possible, as the animated cutscene frames are stored uncompressed - there is no compressed video. Meaning, it should be possible to simply draw subtitles on top of the relevant frames. Syncing it all up with the audio would be most of the work, I think. | |||
| Ginza | Nov 13, 2025 | ||
| Making small progress. I had the 8x16 font working for a while. The game has the routines for printing 8x16 size glyphs only for numbers, but I modified the function so that all hiragana/katakana glyphs were printed 8x16 and replaced the japanese font with a basic roman one (7x10 characters) using the ASCII codes, so you can simply read/write the translated text through any hex editor. The modification messed up the use of numbers however, e.g. in the status screen. It seemed a bit complicated to fix, however in the end was quite simple - just modifying a table. Now numbers seem to work fine! Learned that keeping good notes is essential to avoid redoing stuff if you cannot work continuously on such projects... Getting closer to translate the basic stats/combat/items so that the game can be played a bit. Not sure about the font. To begin with I used a simple 7x10 fixed width system type font. The numbers in the game are 7x14 however, and possibly that would be nicer to settle on. Any suggestions for a 7x14 font, or if people actually consider 7x10 more readable? Before: 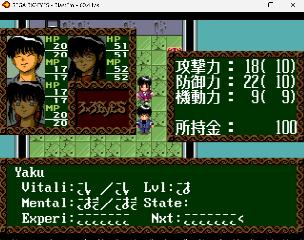 After: 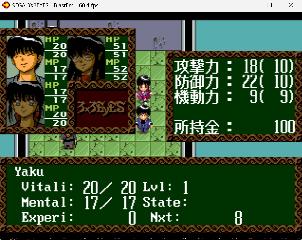 | |||
| Ginza | Nov 23, 2025 | ||
| Some more progress - most of this is just "simple" but extremely tedious tilemap editing and, decompression, editing and recompressing of the Kosinski compressed glyphs stored for each tilemap. Decided to stick with the 7x10 font for now. The translated menus encouraged me to finish the first dungeon and boss for the first time ever! I kind of forgot how difficult some of these old games used to be... It seems the hardest thing will be to find space for expanding all the short item text in the main program binary, where code and data is tightly packed. The scenario text files with all the dialogue lines contains lots of extra space and seems easy to expand - which is nice. I might post a patch when most menus and items are translated, so people can at least navigate the game, and maybe even finish it! Still looking for people interested in contributing! 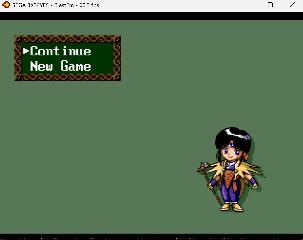 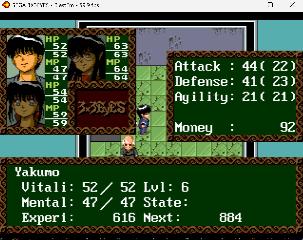  | |||
| Ginza | Dec 6, 2025 | ||
| Here is my work so far in patch form. Please note this is not meant for playing the game, just for debugging. Intro text was machine translated and adjusted to fit (pointers recalculated by hand). Ingame text for first few events has been temp inserted to separate it from control codes etc. for debugging, without any attempt to make it fit - stuff is shortened etc. All japanese text is difficult to read due to the 8x16 function being changed. However, if anyone wants to continue adding text by hand, by all means the 8x16 routine has already been replaced, so you can simply insert ASCII format text over the japanese text (pointers being the large challenge). The table file has been posted on the github linked above together with the source for the script dumper. Hopefully this may increase the interest a bit. I'm considering a small pause. Patch is for the iso/wav dump floating around. | |||
| Ginza | Jan 23, 2026 | ||
| Small update. I translated all the spells/magic and added shortened names in english to the game, see the updated patch. Also started a walkthrough. Should help with navigating the game during hacking/translating, and can probably help anyone adventurous enough to try the game in this state. https://github.com/Ginza25/3x3eyesMCD/blob/main/do... | |||
| Ginza | Mar 2, 2026 | ||
| Significant progress, as I managed to get ChatGPT to make a disassembler and assembler of the text block opcodes and data. For now this applies to the game hint system (which helps you when you get stuck), but it principle it solves the main hurdle for inserting the event text (which is most of the game). Everything was coded in C using ChatGPT, but I did a lot of debugging/research to make this work. I think AI is a huge asset for dedicated fan translators though. Coding the whole disassembler/assembler took 3-4 hours, based on what I knew. Though many hours were spent documenting all the hundreds of opcodes. So it means it's as easy as disassembling the PLAYXXX file (containing all the hint system text), which outputs the opcodes and japanese text with all text formatting codes. For example: text T_6510 terminator=DB encoding=tbl: "<portrait_01><speak><br /><br /></speak><arrow>¨<speak><br /><br /></speak>¨¨<arrow><speak>" endtext Then translate by overwriting straight ascii text - here using Google Translate, just for prototyping text T_6510 terminator=DB encoding=tbl: "<portrait_01>Pai: <speak><br />That's Chen Aguri peeking into the building next to Yougekisha. </speak><arrow>..<speak>So that means Yougekisha is next to the building Chen Aguri is peeking into.</speak>..... <arrow><speak>Pai, it's warm!!" endtext And finally run the assembler to recalculate the offsets of all the inline opcodes used.... and it works...! 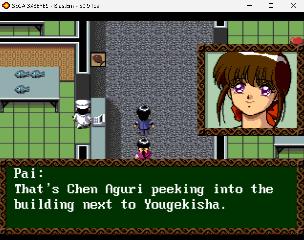 I still need some kind of text editor for editing the output files according to rules of the game (text box size), and possibly with support for text formatting tags. Anyone have any ideas? I'm sure it's easy to make one also using AI, but would be nice if there is an existing package. Still looking for anyone interested in helping! Most stuff is posted at https://github.com/Ginza25/3x3eyesMCD..., though I need to updated with the latest tools. A few more screenshots (showing the lack of formatting rules, I just ran the japanese text with original formatting through Google Translate... and then assembled it again without any adjustment: 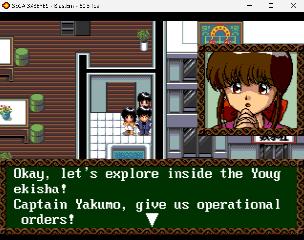 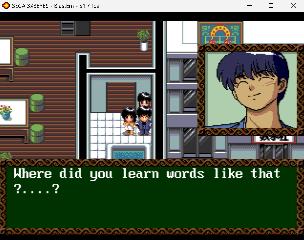 | |||
| Ginza | Mar 4, 2026 | ||
After another hour or so with ChatGPT, I have a text editor which highlights when you exceed the line length, see screenshots directly above, and has some more useful features. I probably want to add a display of the original japanese text as a help to translators. Could also add a simple button to run the assembler and re-insert the file into the ISO. Have been recommended to look into Claude - sounds interesting.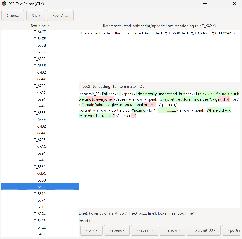 | |||