| Home | Forums | What's new | Resources | |
| Translating Culdcept: tutorials, notes, whatever |
| benclaff - Apr 7, 2024 |
| benclaff | Apr 7, 2024 | ||
| Hi everyone, Following the acquisition of the original disc, I explored a bit the content of the card/board-RPG game "Culcept" and found out that it "might be" relatively easy and straightfoward to translate it to english. In the following thread I will post updates about my finds, but also call for help or advices when I'm stuck. Ultimately, my aim is to translate it. On the other hand, I really appreciated other segaxtreme threads which documented step by step some approach for other translations. This was very helpful to explore my 1st saturn game and might be help to other future enthousiasts. So I decided to make my posts a small tutorial, when possible. And I found that this approach (forum posts) is much much better than having knowledge spread in discord conversations (finding some information a few weeks later is a nightmare...) Current situation is: Confirmed: - main script is in shift-JIS and can be edited relatively easily - a full translation exists for the DS port AND is very well documented here : Culdcept DS translation wiki... - there are minor modifications between both scripts, but not more than a few kanji here and there In progress : - multiplayer mode will need specific re-translation: it is wifi-based in the DS version, while it is local 4 player in the saturn version and there are quite a few differences - it seems that both fixed and variable width fonts are present in the game (needs confirmation, more on this later) - on top of shift-JIS, used for dialog windows, there are some accessory smaller fonts. They do not seems to match any classic fonts, but I may be wrong. Values and offsets need to be determined. Will need help at some point : - how to modify the text routine to switch between variable width and fixed width, depending on context (e.g. dialogs VS menus) SO, after this short introduction. Let's dive into content. ------------------- -------------------- ------------------- ################### ################### PART 1 : Discovery of text encoding ################### ################### Game version used in tutorials : REDUMP lists 2 version:
I had a look at the track files, but there is only 1 small binary file of a few megabytes and 2 large bin files. So I went back to work on the full track dump. All offset below are valid for track_1.bin, sha-1 == 82003c2bf26d23f8824f8934ce5ca9ae403f0043 If anyone has information about any potential difference between these version, please let me know. Tools:
Dialogs font & text replacement :
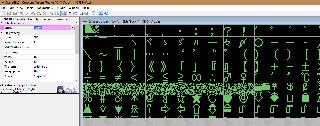 So it may be that the game use the same code as in https://mattsmessyroom.com/uploads/sjis.tbl.... We will test that by searching for a simple japanese word that uses a few easy-to-recognize hirigana or katakana. For instance, will will replace the word "creature" () which appears a lot in the first game dialogs. How did I got this ? (I do not speak japanese) Well, using the deepL app and my phone camera, I observed the dialogs in the 5 first minutes of the main scenario. And I saw that this word appears many times early in the tutorial dialogs. HOWTO :
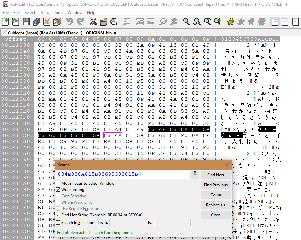
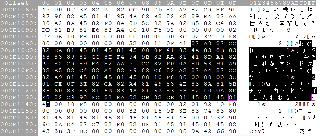
Going further, let's see if modifying some text directly in wxMedit will actually makes the translation to appear in-game HOW TO :
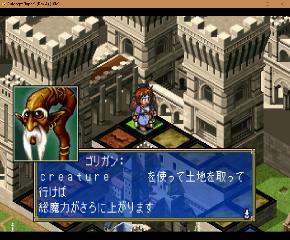 TODO in next updates : - supplementary fonts found via VDP memory exploration - deciphering the dialog control codes - observations related to variable width font in menus | |||
| benclaff | Nov 10, 2024 | ||
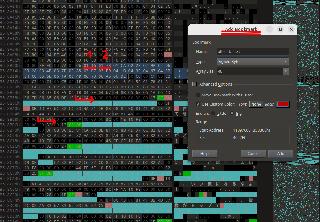
| #################### ################## PART 2 : Control codes / text data structures ################### ################### This next post will show how I explored text data structures and deduced some textbox control codes, cards statistics flags, offset tables, etc ... First, I looked for a good hex editor that would 1) allow me to see text as shift-JIS police (see previous posts) and 2) allow me to highlight some bytes patterns, defined as regular expressions. (If you do not know what is regexp, check Wikipedia, or some good tutorials in whatever coding language you like. For humanity's sake, do not use chatGPT, that burns 20 times more eqCO2 per query...). I went for 010edito which is open source, Mac / Unix / Windows compatible. An equivalent software (open source) would be imhex. After installation, I open the file CULDCEPT.DT0 where we previously spotted some text. Set the byte translation to shift-JIS : View -> Charset -> International -> select shift-JIS My first regexp will match bytes translation intervals of the shift-JIS police, e.g. one single byte interval (Latin characters mostly) and several 2-bytes (Japanese) characters. You can observe the full shift-JIS byte translation and these intervals there: (picori::shift_jis_1997 - Rust...), bytes intervals are basically 1-byte ([x81-x9F] | [xE0-xEF]) & 2 bytes ([x81-x9F] | [xE0-xEF])([[x40-x7E]|[x80-xFC]]). You can notice that value 7F is excluded for 2nd byte. That would be a few intervals to enter, but for quick exploration, I summarize this to interval [x8140-x9FFC] which is more than shift-JIS but OK for this tutorial. I created a "highlight" in the editor to background colour whatever matches this interval. When translated to base 10 (decimals) this 2-bytes interval (also named shorts in 010editor) match [33088-40956]. Go to menu View -> Highlight -> Edit Highlights, remove existing entries and create a new one, as a 'short' (2-bytes) value and select a colour (I used clear blue). I also entered some control code that I spotted earlier, eg. x0A for line return, x07 for wait_button_input (both in red), and interval [xF00-xFFF] which looks to be character portraits displayed on top of the dialog window (in green). 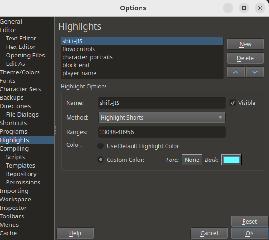 Now my aim is to scroll down in the bytes with page_down key and find some large coloured blocks, which will probably be text-related. The right summary pane is helpful for that. In Culdcept's case, we are lucky because texts are grouped in relatively dense blocks and not compressed, and text structures appear rapidly. See the image ? Look at this big block full of blue, that's probably some text block !  You will notice that the highlight tool is rather limited, as soon as a 1-byte control code is following 2-bytes characters, the highlight tool is 1byte shift and will not highlight in blue until the next 1-byte shift. But this is enough to spot blue blocks. After full file scrolling in the opened file, I listed 21 text blocks. After copying a few words from each block and searching for matches in the existing Nintendo DS translation wiki, I managed to associate each block to a text category (scenario, taunts, cards, items...) and determine their offsets. This is a long work. All together, I probably spent around 6 hours to reach this step. Weirdly, 6 blocks are a repetition of the scenario text, all with exact same bytes (data packing oversight from the developers, I suppose). Now let's dig into text data structures. I found 3 general patterns : 1) offset tables + dense text : easy to guess as you will see (scenario, tutorials). 2) pointer tables + dense text. There is more than control codes here, some bytes blocks between texts have some function. 3) Data/text mixed tables, with pointer and/or tables : short text are in the middle of structured game assets, such as cards, items, spells statistics... Next post will detail pattern 1. ################### ######## ## Text data pattern n°1 This is the simplest text patterns. We are going to use the "tutorial" text as an example. Have a look at this screenshot taken from position xC0B9C0, which is the "Scenario" text.  You can clearly see the text block in blue (full block on the summary pane on the right, beginning og the block in the hexadecimal pane) with control codes appearing in red/green. We could already start translating via 010editor from here, but with a strong limitation : we would have to stick to the same byte sizes for each text. Meaning that if a text was 14 bytes long (so 7 shift-JIS jap characters, as they are 2 bytes long), we could at best replace them with, at best, 14 Latin characters (they are 1-byte in shift-JIS, e.g. ASCII-compatble). Could we hope for more freedom ? Well so far I found that yes, but not much more. We are stuck by the fact that all data is packed in 1 file and until someone guess the packing format (not me) we will have to fit English translation into the limits of these blue blocks. But, we would be happy to get some freedom to shift text blocks to our convenience in this interval, because some sentences, when translated from Japanese to English, might need more characters, while others might need less. Did you notice something with the bytes just before the text block ? Have a close look to each pair, can you guess a pattern ? Some clue, look values every 2 bytes. [try before going to next senetence !] So x00F0, x030D x0607 x06CA ... until x6116, x622A, x0765. Then starts the text. These are systematically increasing values ! x00F0 < x030D < x0607 < x06CA < ... < x6116 < x622A < x0765. Let's take adress of 1st pair x00F0, which is located at address xC0B9C0 : C0B9C0 + 00F0 = address of 1st sentence ! More Precisely x0F02 which is character portrait followed by text (spoiler, x1307 is replaced by platyer name). Let's take the second : adress of 00F0 (C0B9C0) + 030D = 2nd block of text !  So we may have a way to set where is starting each text block. With a bit of scripting, that will allow us to build tools to modify this text with more freedom. Also, you will notice that each sub-block targeted by this list of offsets is ending with x00 (highlighted with black background in my screenshot). If you had launched the game and had compared the text you would have confirmed that the 1st sub-block is the 1st conversation of the game ( on the world map). The second is the 1st conversation at the start of the 1st battle ... etc... Now, let's modify bytes to confirm we guessed everything correctly. I modified sub-blocks 1 and 2. I changed their text, but also some portraits and offset of block 2. Basically the dialog on world map (1st sub-block) will be much shorter and dialog in 1st battle intro (2nd sub-block) will be longer. I used Sega Saturn Patcher from KnighOfDragon, using Malenko's tutorial... to patch the image with the modified CULDCEPT.DT0 file. Here is the result, recorded from Mednaffen.  | |||



| benclaff | Nov 10, 2024 | ||
| #################### ####### ## Text data pattern n°3 [placeholder] | |||
| benclaff | Nov 23, 2024 | ||
| #################### ################## PART 3 : more fonts in VDP memory ################### ################### [placeholder] | |||
| benclaff | Nov 23, 2024 | ||
| #################### #################### ######### PART 4 : notes on tooling (shift-JIS & python) ################### #################### ########## [placeholder] | |||
| Malenko | Dec 30, 2024 | ||
| I removed my reply, it was ruining the flow of the thread and something you already knew. Love the tutorial sections, keep it up! | |||
| OfManNotMachine | Apr 23, 2025 | ||
| Very excited for this! Thanks for working on it!! | |||
| giloi | May 18, 2025 | ||
| Culdcept deserves a translation, thank you so much for your support | |||
| Hiroshi Takahashi | Jul 2, 2025 | ||
| You still updating your post for some status updates about the project? | |||
| Reddha | Jul 8, 2025 | ||
| Congrats on the new baby! | |||
| Hiroshi Takahashi | Sep 23, 2025 | ||
| Is this project still ongoing? | |||